Darkflow를 활용하여 YOLO 모델로 이미지 디텍션 구현(윈도우 환경)
나의 데이터를 이용해 YOLO 모델을 학습시키기
YOLO(You Only Look Once) - Object detection networks model
영상 인식에서 이미지로부터 특정 객체의 위치 영역(Boundary-box)을 감지하면서, 해당 영역 내의 객체를 분류하는 작업을 Object Detection이라고 한다. 딥러닝을 이용한 Object Detection 접근법에는 대표적으로 R-CNN, YOLO, SSD와 각각의 변형들이 있다. 이번 글에서는 YOLO 모델을 이용하여 자신의 데이터 및 도메인에 Object Detection 문제를 해결하기 위한 방법을 다루며, YOLO의 자세한 이론적 방법론은 생략한다.
YOLO에 대한 자세한 모델 설명 및 방법론은 해당 논문 및 공식 홈페이지를 참고하기 바란다.
문제 정의
…
학습을 위한 Data-set
해결하고자 하는 문제에 필요한 데이터를 직접 찍든, 이미 존재하는 이미지를 다운 받든 자신만의 방법으로 데이터를 수집한다.
Image boundary-box labeling
YOLO모델을 supervised learning에 속한다. 따라서, 가중치 학습을 위해 각각의 학습 이미지에 desired output 즉, 정답을 할당해주어야 한다. Object Detection 문제의 경우 정답 레이블은 각 객체의 class label과 boundary-box의 쌍들로 구성되며 이를 Annotation이라 부른다. 이미지에 Annotation을 할당하기 용이하도록 돕는 다양한 도구들이 존재한다. 여기서는 labelImg라는 Python 및 Pyqt 기반의 프로그램을 사용한다.
- labelImg : 이미지 labeling을 위한 도구
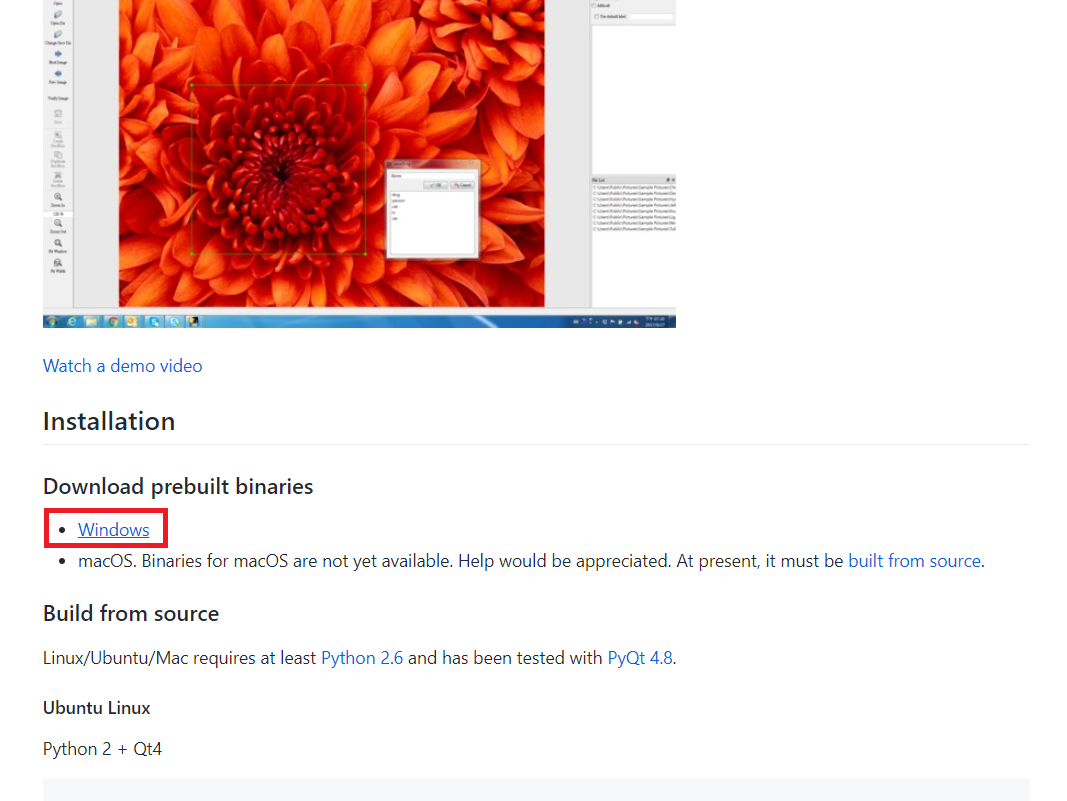
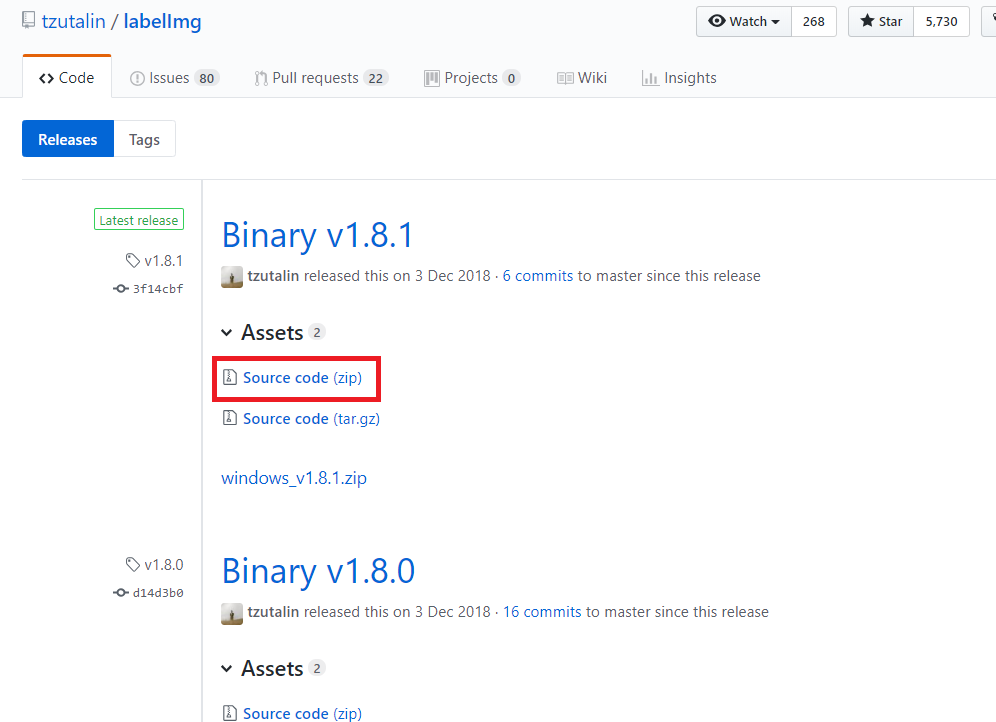
labelImg 도구는 github에서 쉽게 다운로드 받을 수 있다.
다운로드 받은 labelImg 압축파일을 압축해제 한 후 가장 먼저 할 일은 data 폴더 내의 predefined_classes.txt 파일에 자신의 클래스 목록을 지정하는 것이다.
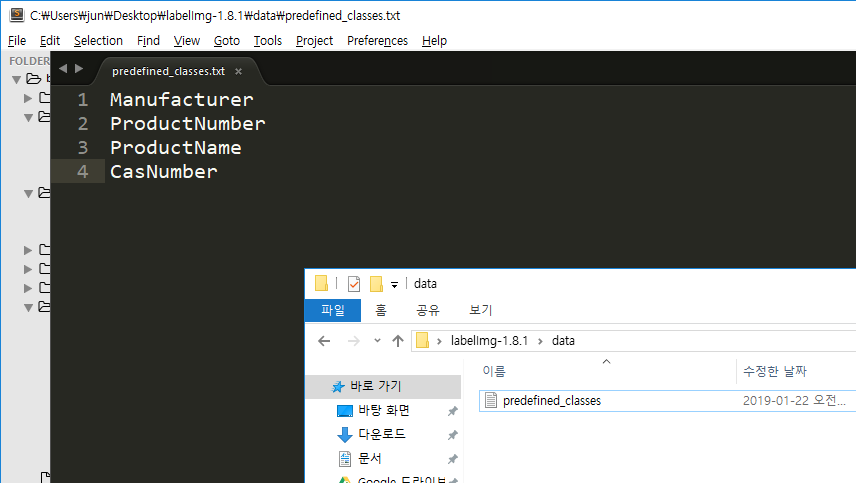
윈도우 환경의 경우에 문서를 저장할 때, 명시적으로 _utf-8_ 인코딩 형식을 지정해주는 것이 이후 작업을 진행하는 데에 있어서 안전하다. 이 외의 포멧으로 문서를 저장할 경우 darkflow 실행 과정에서 디코딩 문제를 직면할 수 있으니 주의하자.
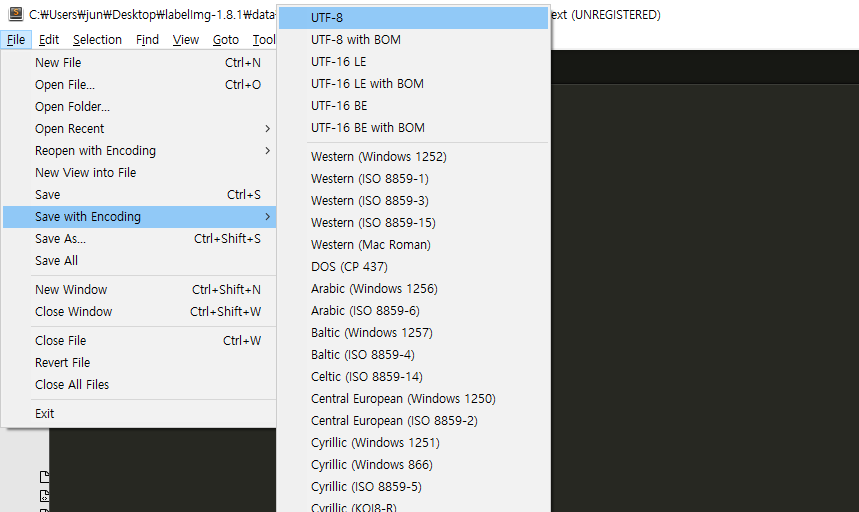
predefined_classes를 수정하였다면, 이제 Console창 이나 Anaconda Prompt에서 labelImg.py가 있는 폴더로 경로 이동 후 labelImg.py를 실행하면 된다.
>python labelImg.py

labelImg를 실행하였으면 Open Dir 버튼을 통해 labeling을 수행한 이미지가 있는 폴더를 실행시킨다.

W 단축키를 이용하거나 Create RectBox 버튼을 통해 Bounding-box를 지정할 수 있다.
원하는 수의 Bounding-box를 지정한 이후에 (PascalVOC 형태로)저장하면 해당 이미지에 대한 레이블 정보가 담긴 annotation xml 문서가 생성된다. 문서에 저장되는 정보는 아래와 같다.
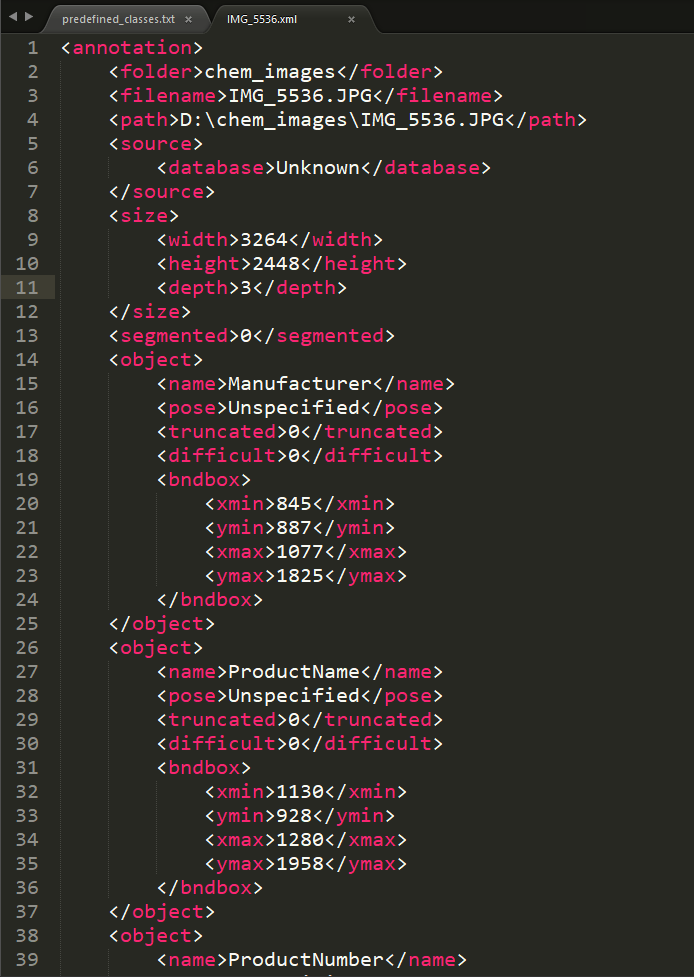
이제, 보유한 이미지들에 대해 끈기를 가지고 Annotation 생성 작업을 진행하면 된다…
Darkflow - Predefined YOLO model using tensorflow
학습을 위한 darkflow 준비
Python으로 구현된 YOLO 모델이 darkflow이다. darkflow를 이용하면 직접 딥러닝 구조를 구현하지 않아도 모델을 학습할 수 있다.
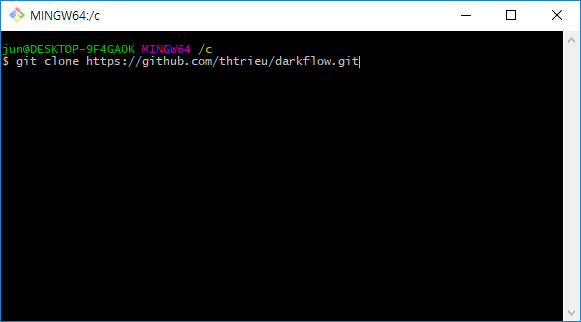
우선, git을 이용하여 darkflow의 github repository를 받는다.
git clone https://github.com/thtrieu/darkflow.git
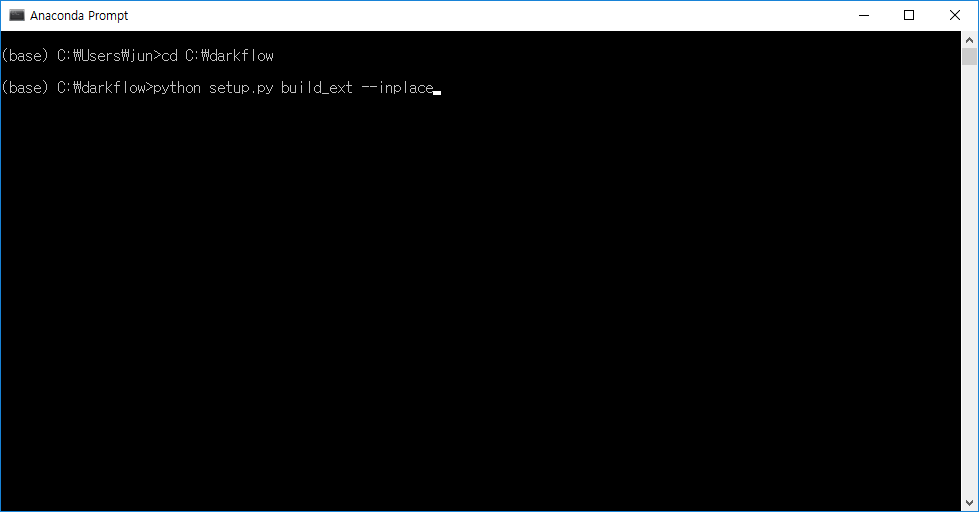
Anaconda Prompt나 console에서 darkflow 폴더로 이동한 후 setup.py를 빌드 해준다.
python setup.py build_ext --inplace
pip install .
이 과정에서 문제가 발생하는 경우가 종종 있는데, 대표적인 예로는 윈도우에 C++ SDK가 설치되어 있지 않는 경우이다. 이럴 때는 Visual Studio install tool을 이용하여 c++ SDK를 설치해주고 다시 진행하면 된다.
정상적으로 빌드가 완료되었을 경우
Training
이제 darkflow를 사용할 준비가 완료되었으니 학습을 위해 몇 가지 내용을 수정해줘야 한다.
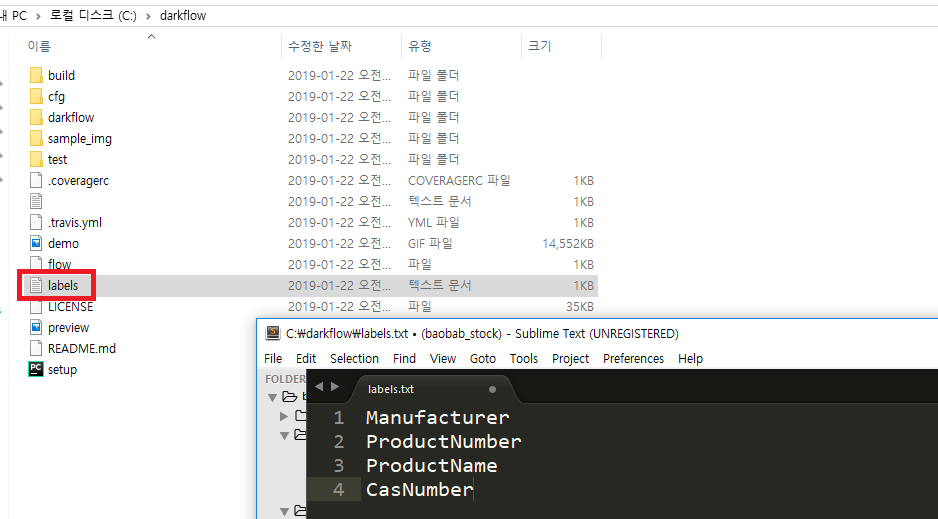
가장 먼저 darkflow 폴더 내의 labels.txt 문서를 labelImg에서 처럼 자신의 클래스 목록으로 수정해준다. 이 때도 utf-8으로 명시적으로 인코딩 형식을 지정해주는 것이 안전하다.
다음으로는 darkflow/cfg 폴더 내의 cfg 중 사용할 모델의 cfg를 자신의 문제에 맞춰 수정해줘야 하는데, 원본을 훼손하지 않기 위해 복사한 후에 수정하기로 한다.
수정해야 할 내용은 filters 와 classes 값으로 우선, classes는 정의한 문제의 클래스 수를 지정하면 된다. filters는 (5+classes)9 로 설정하면 된다. 예를 들어 classes가 4인 경우, filters = (5+4)9 = 45 가 된다.
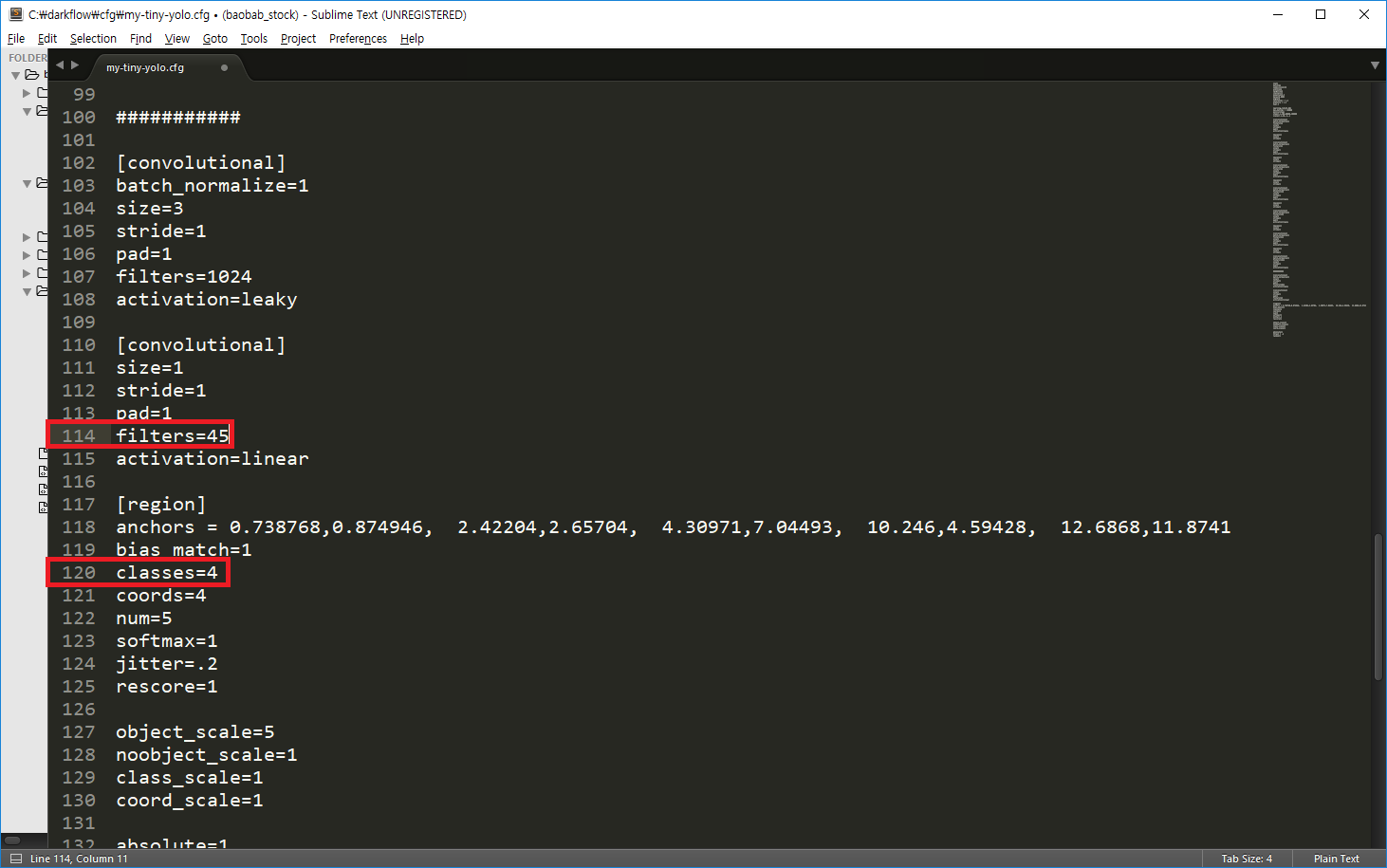
filters를 이렇게 설정하는 이유를 모른다면 YOLO youtube 영상을 참고하자.
마지막으로 학습 데이터를 아래와 같이 두 개의 폴더를 이용하여 이미지 데이터를 위한 폴더와 anntation을 위한 폴더로 나눠서 준비하자.
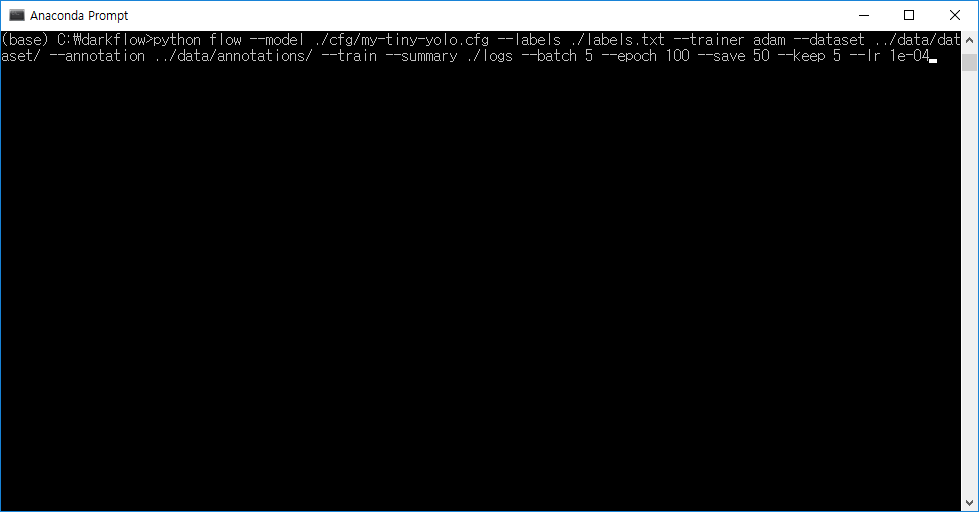
이제 학습을 위한 준비가 완료되었으니, darkflow 폴더 에서 아래와 같은 명령어를 통해 학습을 시작하면 된다.
처음 가중치를 학습 할 경우:
python flow --model ./cfg/my-tiny-yolo.cfg --labels ./labels.txt --trainer adam --dataset ../data/dataset/ --annotation ../data/annotations/ --train --summary ./logs --batch 5 --epoch 100 --save 50 --keep 5 --lr 1e-04 --gpu 0.5
이 전에 학습된 가중치를 이어서 학습할 경우:
python flow --model ./cfg/my-tiny-yolo.cfg --labels ./labels.txt --trainer adam --dataset ../data/dataset/ --annotation ../data/annotations/ --train --summary ./logs --batch 5 --epoch 100 --save 50 --keep 5 --lr 1e-04 --gpu 0.5 --load -1
–trainer : optimizer 설정
–lr : learning rate로 1e-04는 0.0001을 의미한다.
–gpu : gpu 사용 여부, gpu가 없는 환경이라면 옵션을 제외하면 된다.
–load : 이전 학습 가중치를 이어서 학습하겠다는 옵션으로 -1은 마지막 save를 불러온다. 특정 step부터 시작할 경우 저장된 step의 값을 명시적으로 입력하면 된다.
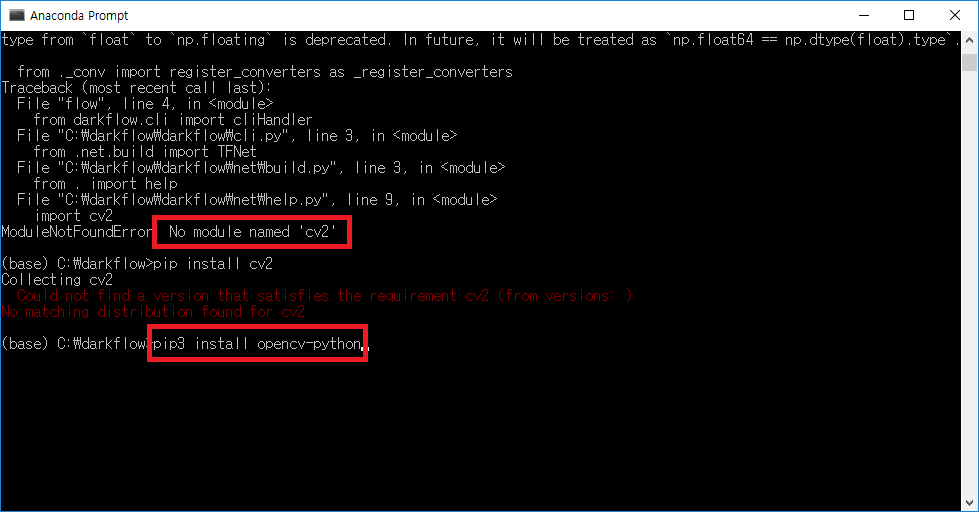
opencv 모듈이 설치되어 있지 않을 경우 pip를 이용하여 opencv-python 모듈을 설치해주면 된다.
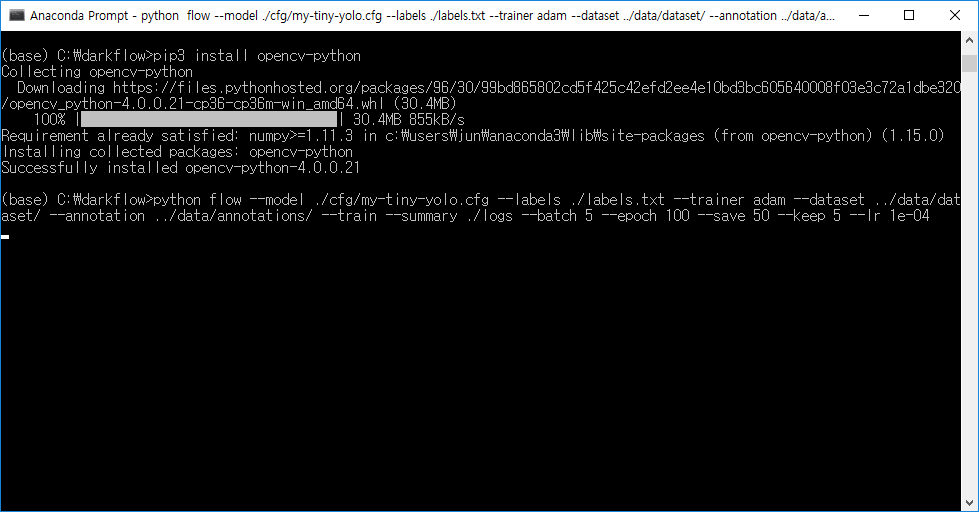
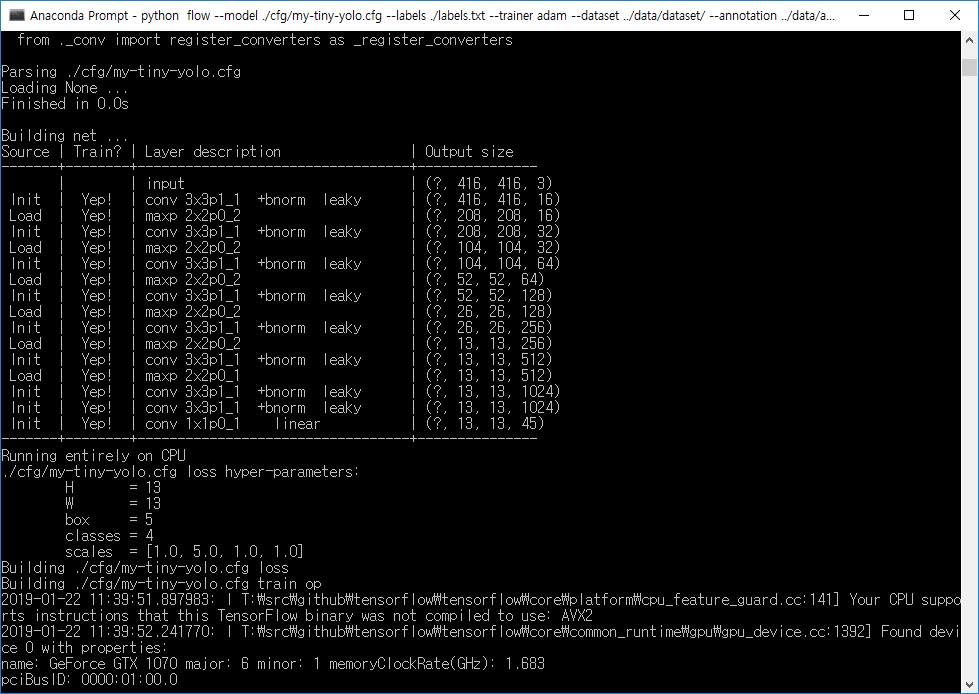
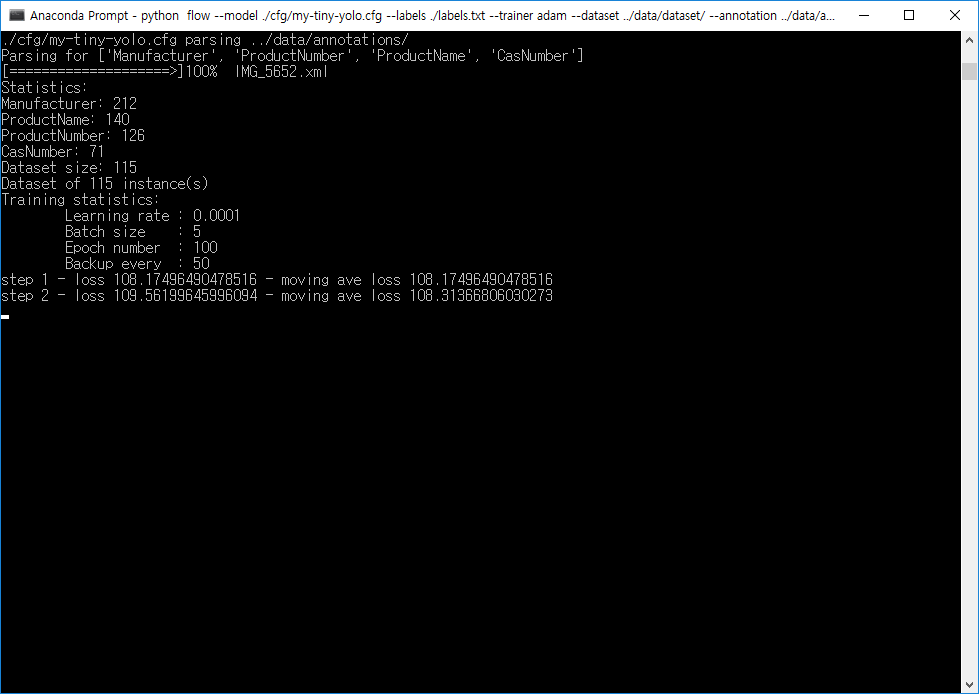
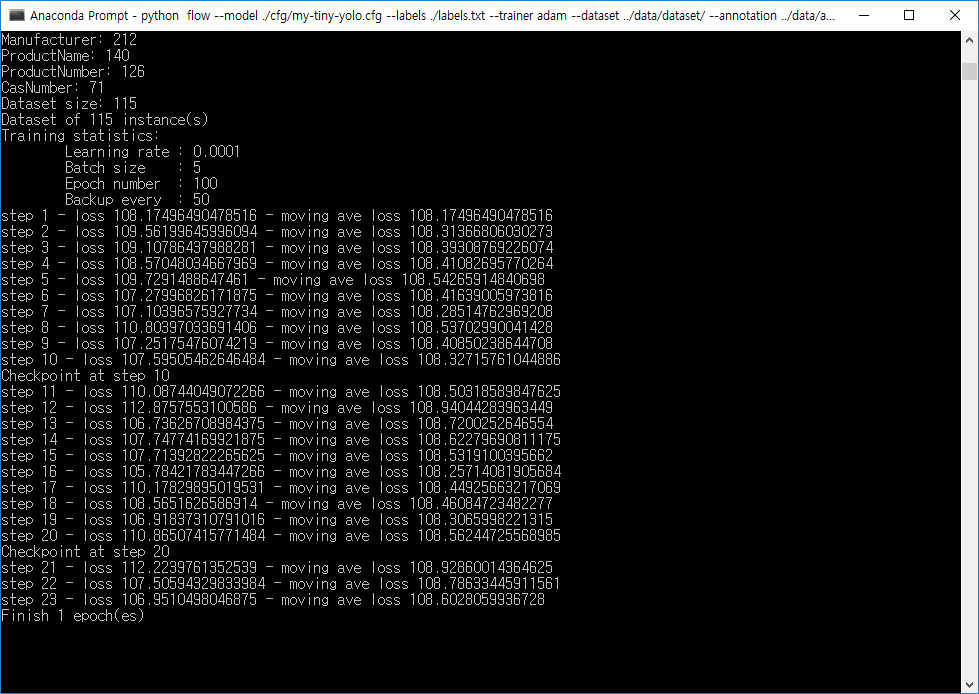
정상적으로 학습이 시작되었다.
TensorBoard를 이용하여 학습에 따른 epoch 별 loss의 변화를 확인 할 수 있다. 잘~ 수렴한다.
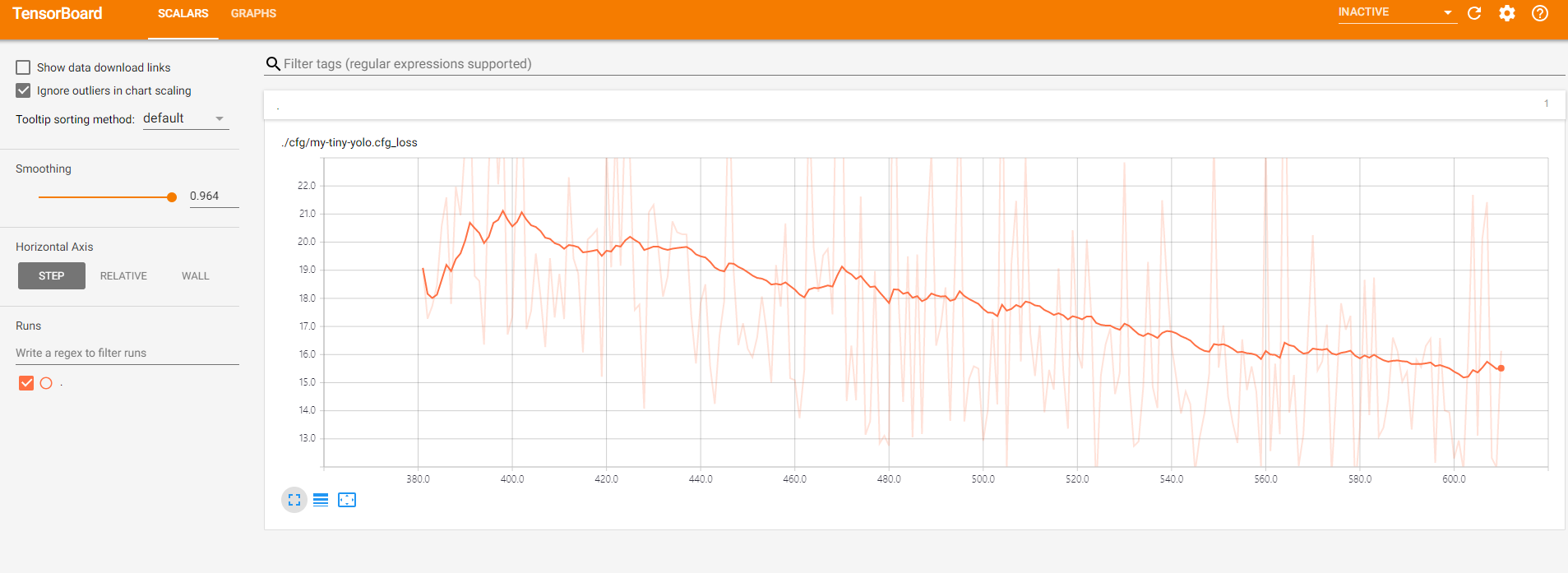
prediction(detection)
학습이 어느 정도 진행 된 후에 이미지로부터 Object Detection을 수행하고 싶다면 아래와 같은 명령어를 통해 실행하면 된다.
python flow --imgdir ../data/testset/ --model ./cfg/my-tiny-yolo.cfg --load -1 --batch 1 --threshold 0.5
–threshold 0.5 는 confidence가 0.5보다 높을 경우에는 boundary-box를 수용하겠다는 의미이다. 다시 말해, 특정 부분에 객체가 존재할 확률이 0.5 이상이라고 예측할 경우에만 박스를 그린다.
- 1430step 정도 수행한 후 threshold를 0.5로 설정하고 예측한 결과 :

아무런 Boundary box도 그려지지 않았다. 이 당시 loss는 10.0 미만이었다.
- 1430step 정도 수행한 후 threshold를 0.03로 설정하고 예측한 결과 :

threshold를 아주 낮게 설정하고 예측하였더니 box는 그려지나 예측 결과는 매우 나쁘다는 것을 확인 할 수 있었다. 사실, 이 때까지만 해도 학습이 정말 되긴 하는 건가 의구심이 들었다.
그래서 검색해본 결과,
- No box after train problem
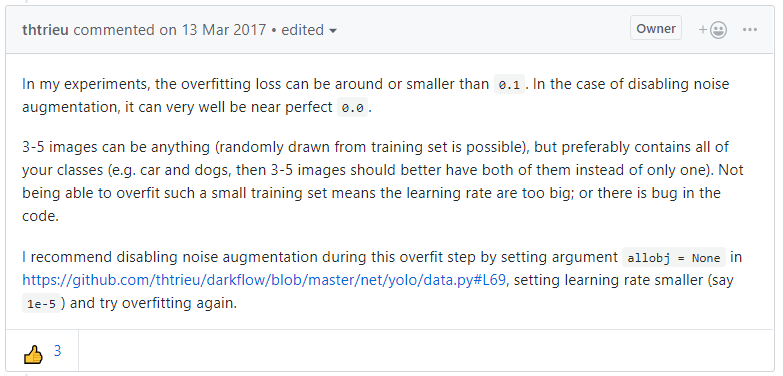
일단 학습 잘 하면 loss가 0가까이 내려간다고 한다.
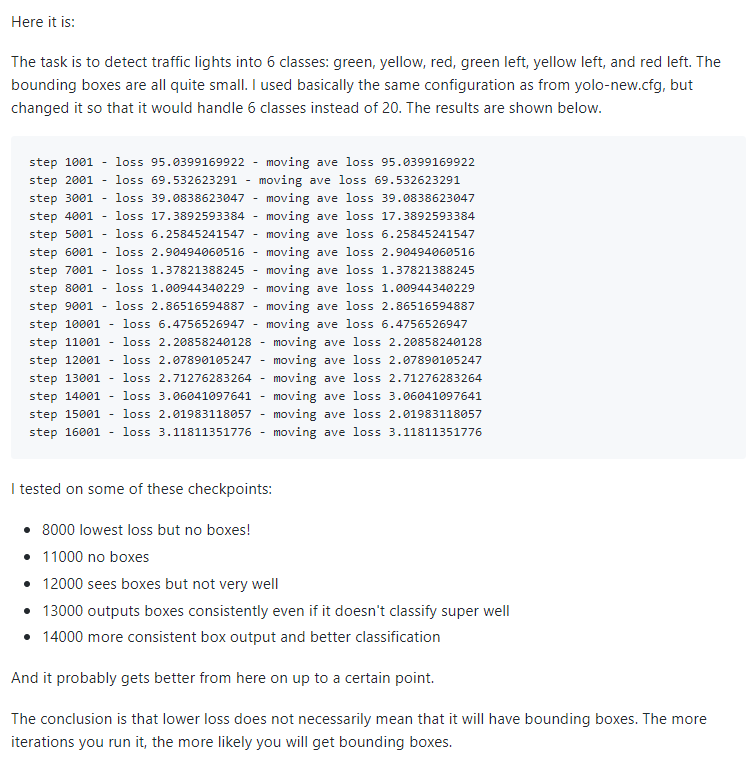
loss가 어느 정도 수렴해도 지속적으로 학습을 수행해야 성과를 얻을 수 있다고 한다. 많은 최적화가 필요한 작업인 것 같다.
출처 : https://github.com/thtrieu/darkflow/issues/80#issuecomment-303931206
일단, 믿고 계속 학습해보기로 한다.
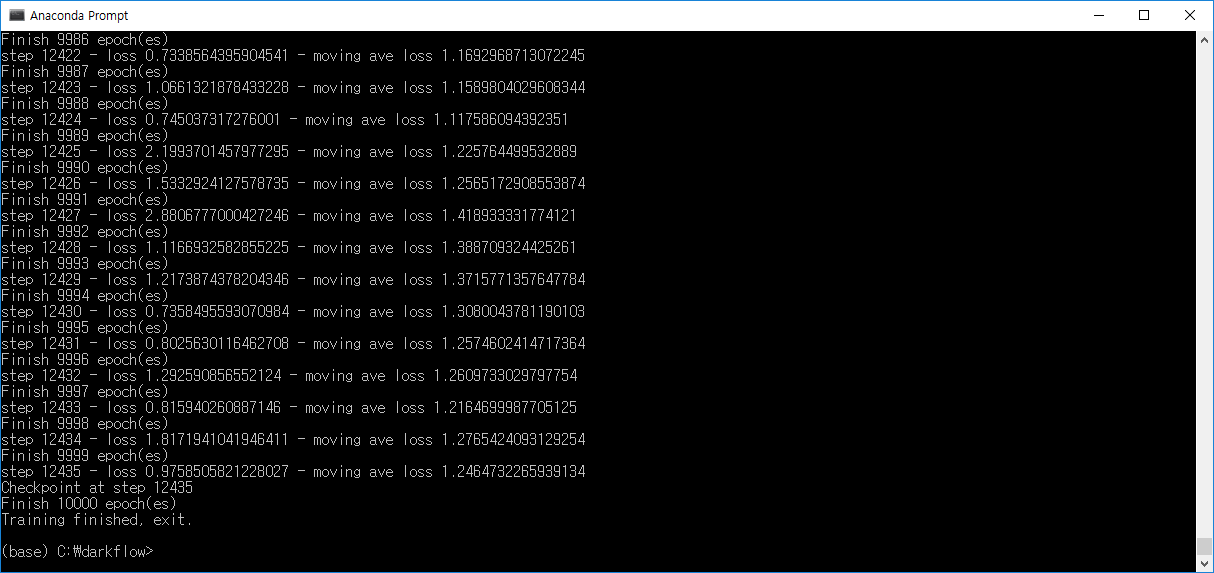
10000step 정도 추가적으로 학습하여 가중치를 최적화 하였더니 loss가 1에 가까운 값까지 떨어졌다.
이 상태에서 예측한 결과:

완벽하지는 않지만 제법 잘 찾아내는 것 같다. 이제 모델이 학습된다는 것을 눈으로 확인하였으니 img augmentation을 통해 학습 데이터를 증폭시키고, 더 큰 yolo 구조를 사용하여 개선된 모델을 만들 계획이다.
[학습팁]
처음 학습에는 learning rate를 크게 설정(대략, 1e-02 or 1e-03)하여 loss를 10정도까지 떨어뜨릴 것. 이 후에는 learning rate를 낮춰서(대략, 1e-05 or 1e-06) 계속 학습한다.
loss가 수렴해도 계속해서 학습할 것 - 이미지 3~4개에 대해서도 최소한 10000-15000 step은 학습을 해야하는 것 같다.